
[2023TPCTF]Walk Off The Earth复现
Walk Off The Earth
这道题引入了一个概念,工作量证明(Proof of Pow),也就是第一个考点。
1 | app.post('/visit', async (req, res) => { |
即计算一个类似方程的表达式:
1 | sha256(一些前缀字符 + ???) 的前difficult位都是0 |
所以difficult越大,计算难度也就越大,那么如果我们找到了一个符合条件的字符串,那么就代表你通过计算完成了一些工作,系统就会给你一些奖励。
之前没接触过区块链,所以做这道题时看到需要哈希碰撞就以为走不通,但是事实这种difficult下的计算对于现代计算机的算力来说小事一桩。
现成的Pow强度检测工具
使用时要注意,0的个数是以byte为单位的,所以题目给出的difficult为7,就是前7位字符要求是0,而sha256的一般表示都是hex形式,所以对应的就是4*7=28位
1 | solver-multi {req.session.pow} 28 |
第二个考点就是突变型Xss(mXss)的利用
之前一直没接接触过这种类型的XSS利用,这有一篇利用mXSS绕过DOMPurify(一个XSS过滤库)的文章,可以帮助我们很好的理解这种奇妙的trick
强烈建议先看上述文章
比如有一个论坛,发生了以下事件:
用户A在一个帖子下发表了一个评论,评论内容为:
1
<p onmouseover="alert(1)">楼主说的很有道理
评论的内容以字符串形式传入到论坛服务后端系统后,开发者做了处理,其中在安全环节使用某种基于DOM解析的方式进行XSS过滤
- DOM解析器准备将其解析为一个个tag(如果有),准备对
<p onmouseover="alert(1)">进行解析时,由于用户A并没有对其进行闭合</p>,所以DOM解析器只把它认为是一个普通的字符常量,而并不认为是一个具有XSS威胁的标签。 - 解析并处理完毕后,DOM解析器将DOM结构序列化为新的字符串(然而这里没有任何改变),在序列化时,DOM解析器发现p标签没有闭合,于是贴心地在结尾补全了闭合标签
</p>,最终返回给调用者 - 开发者用innerHtml将其输出并解析在帖子的某个楼层中
- DOM解析器准备将其解析为一个个tag(如果有),准备对
其他用户访问该贴时,浏览或者加载到用户A评论的那一层时,受到XSS攻击。
事实上,笔者举得这个例子在日益完善的框架下不太可能发生,因为开发者不太可能只处理tag而不处理attribute,但为了简单的描述mXSS的本质,所以举了这个不太可能存在的例子。
还有一点,这种帮助补全标签的操作在开发者使用DOM序列化操作和浏览器自动补全时都有可能发生。
DOMPurify的mXSS的利用固然比笔者的例子高级很多,但究其本质都是利用old html_code->DOM->new html_code(DOM解析->序列化->浏览器解析)而old html_code不一定等于new html_code造成的差异性来XSS。只不过是两者利用的差异性不同。
命名空间混淆
通过命名空间混淆来mXss的本质就是html空间和math空间两者对于style标签下的子元素的解析方式不同:

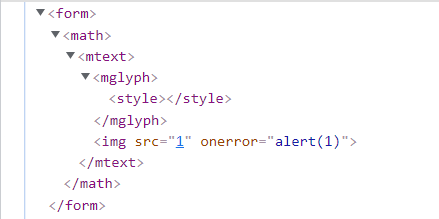
红框里的style的父元素是mglyph,而mglyph标签作为mtext的直接子元素时并不会将math空间切换为html空间,所以此时style依然处于math空间,而math空间会将style标签中的带有尖括号<>的code视为一个正常的标签。
蓝框里的style的父元素是mtext,而mtext标签在一般情况下会将下一个元素的空间切换为html空间,所以此时style处于html空间,而html空间会将style标签中的任何内容都视为CSS样式代码。
综上所属,同样的标签<img>,在不同的命名空间中一个被解析为正常的标签,而另一个被当做CSS样式代码,这里也可直接视为文本。
以上是导致mXSS的根本原因,但还有一个不可或缺的核心要素,它就是利用form表单的不可嵌套性质,才造成了前后的解析差异。
form嵌套
由于HTML语法规范,在正常情况下,HTML语法解析到一个form标签时,会将一个与form相关的的指针置为1,当在指针不为null的情况下,又遇到了一个form标签时,他会自动忽略此标签并将其内容合并到首个form标签中
1 | <!-- 原语句 --> |
所谓form嵌套,其原理就是在不同的标签层级中手动关闭form指针,导致其为null,而又因为在不同的层级使用</form>,导致应该闭合的form标签安然无恙。(HTML语法解析的设计问题所致)
1 | <!-- 原语句 --> |

最终Payload
根据上述内容,我们可以先进行mXSS的测试
1 | /note?text=<form><math><mtext></form><form><mglyph><style><img src=1 onerror=alert(1)> |
注意有些浏览器(比如QQ)会自动进行HTML转义导致失效,遇到这种情况请更换其他浏览器
在JSDOM将text中的code解析为DOM树时,会将其解析为以下形式

此时由于mglyph不是直接作为mtext标签的子元素,所以内嵌的form以及之后的子元素均在HTML命名空间下,style中的内容被视为CSS样式代码,自然不会被iter.nextNode()捕获
检查完后,JSDOM会将DOM结构序列化为
1 | <form><math><mtext><form><mglyph><style><img src=1 onerror=alert(1)></style></mglyph></form></mtext></math></form> |
这里注意<mtext><form>之间的</form>在序列化时被剔除了,导致浏览器在解析时触发form表单无法嵌套的性质,则夹在<mtext>和<mglyph>之间的<form>在浏览器解析时也被剔除了,然后mglyph标签理所应当的成为了mtext标签的直接子元素,所以之后的style标签依然处于math空间,而我们说过,math空间允许在style标签中嵌套子元素。
虽然html解析器还是将style中的元素img解析到了style之外,但并不影响造成XSS的结果。
在 visit方法中,必须想办法使其抛出异常,否则res将被替换为ByeBye,而我们注意到它配置了超时,所以我们可以写一个无限循环使其timeout
1 | /note?text=<form><math><mtext></form><form><mglyph><style><img src=1 onerror=while(true){console.log(1)}> |
但是当我把这个payload扔到post里让visit执行时,发现并没有起效(没有报TimeoutError)。但如果通过get方法传text在本地浏览器上执行的话,是有效果的

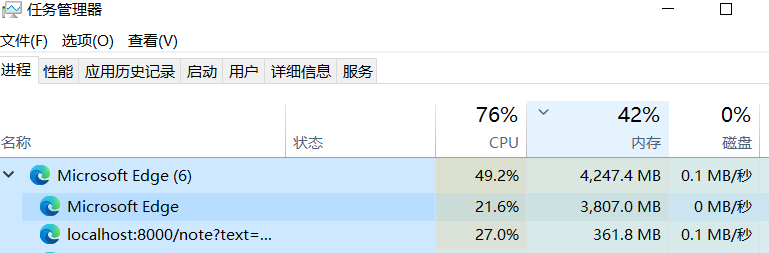
几秒之内CPU飙升,说明本地是可以这么做的。
最后,倒头一看,发现是math空间没闭合,导致style的子元素没有切换到html空间,而原payload长这样
1 | <form><math><mtext></form><form><mglyph><style></math><img src onerror=alert(1)> |
经过大量的测试,我发现以下几点
- math空间中,
<script></script>中的js会被忽略,但是on事件依然可以正常触发,所以正常来说即使我不闭合math,也应该是可以成功的 - 在puppeteer模拟浏览器行为时,由于某种未知原因,
<img>on事件无法进行while(true)这样的死循环操作,但是在script标签中却可以这么做 - 综上2点,我们需要使用script标签来执行js代码,前提是要手动闭合math标签使script处于html空间中。
所以最后的payload为:
1 | /note?text=<form><math><mtext></form><form><mglyph><style></math><script>while(true){}</script> |