
基于LazyList的Scala反序列化漏洞透析(CVE-2022-36944)
引言
前段时间打SCTF,欣赏大牛师傅们的WP时,发现在hello java那道题使用了CVE-2022-36944这个漏洞,但是查阅资料在国内乃至全世界互联网中没有找到相关分析文章,在github上找到了1个复现项目环境,研究了一些时间大概懂了一点。
没接触过Scala语言,虽然和java兼容性很强,但很多语言特性和机制都是第一次接触,而且有段时间没搞java安全了,这次相当于没有现成的分析文章,只能硬着头皮啃
POC复现环境
Github:
“线索”
For security, prevent Function0 execution during LazyList deserialization
关于这个CVE的最详细的信息就是这位CVE发现者提交的issue,所以我能挖掘到的一切关于这个CVE的信息都是基于上面的POC环境和这个issue
利用条件
- scala版本<2.13.9
- 允许用户伪造序列化字节流数据
前置知识
对于我本人来说,要钻透某个漏洞的话就必须要搞清楚是哪一步产生了漏洞,那么前提就是要了解这个漏洞产生流程的大框架,否则只针对链子上某点出现的反序列化干分析不仅枯燥难懂而且总感觉少了点什么
有Scala基础的师傅可以直接跳过这部分
Scala简介
Scala语言是一门多范式的编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性。Scala运行在Java虚拟机上,并兼容现有的Java程序。Scala源代码被编译成Java字节码,所以它可以运行于JVM之上,并可以调用现有的Java类库。
Scala和Java之间的联系很紧密,Scala可以看作是对Java语言的丰富和扩展,Scala比Java更加灵活和强大,支持更多的编程范式和语言特性,例如高阶函数、模式匹配、特质、偏函数、隐式转换等。
这个特性对于经验丰富的scala开发者来说很舒服,但对于第一次接触scala就要啃源码的人来说非常非常非常不友好,比如笔者
Scala也可以利用Java的丰富的生态系统,使用Java的各种框架和库。
Scala和Java之间的区别也很明显,Scala有自己的语法规则和风格,与Java有很多不同之处,例如变量声明、函数定义、类构造、异常处理、集合操作等。Scala还有一些Java没有的概念,例如伴生对象、样例类、富接口、自身类型等
基础语法即使不懂scala也差不多能看懂,所以不涉及语法糖或者比较新的机制的地方本篇文章不做论述
但scala代码的有些地方还是容易迷糊,所以在之后部分涉及到的语法看不懂的可以先自行学习一下
匹配器match
Scala语言的匹配器match是一种强大的语法结构,它可以让你根据不同的条件对一个值进行分支处理,类似于Java中的switch语句,但是更加灵活和强大。
match的基本用法
1 | // 定义一个值 |
当然,你也可以用其他字符表示默认结果,而与_的区别就是_作为接受其他情况的变量时不会赋予$_值
1 |
|
match可以匹配不同类型的值,比如整数、字符串、布尔值等,也可以匹配复杂的数据结构,比如列表、元组、样例类等。match还可以使用模式守卫来增加额外的判断条件,比如:
1 | x match { |
match的其他用法
1 | // 把match赋值给一个变量 |
总的来说,match是一个表达式,它有一个返回值
apply方法
apply方法是Scala中一个非常有用的特性,它可以让我们用一种简洁而直观的方式来创建和使用对象。
apply方法的本质是一个普通的方法,它可以定义在类或者对象中,但是它有一个特殊的语法糖,就是当我们用括号传递参数给一个类或者对象时,Scala会自动调用它的apply方法,并把参数传给它。
例如:
1 | // 定义一个类Person,有一个name属性 |
我们通过Person(“Alice”)这种方式创建了一个Person实例,而不需要用new关键字。这是因为Scala会把Person(“Alice”)转换成Person.apply(“Alice”),也就是调用了伴生对象Person的apply方法,并把”Alice”作为参数传给它。这样就可以省略new关键字,让代码更简洁。
apply方法不仅可以定义在伴生对象中,也可以定义在类中。当我们对一个类的实例用括号传递参数时,Scala会调用该类的apply方法,并把参数传给它。
1 | object Main { |
伴生对象
伴生对象是Scala中一种特殊的单例对象,它与一个同名的类存在于同一个文件中,这个类被称为伴生类。
伴生对象和伴生类之间有以下几个特点:
- 伴生对象和伴生类可以互相访问对方的私有成员,包括字段和方法。
- 伴生对象的成员相当于Java中的静态成员,可以直接通过对象名调用,而不需要创建对象实例。
- 伴生对象可以实现apply方法,用于创建伴生类的实例,这样就可以省略new关键字。
- 伴生对象可以实现unapply方法,用于实现模式匹配和提取器的功能。
- 伴生对象可以扩展一个或多个特质(trait),从而实现多重继承和混入(mixin)的效果。
下面是一个简单的例子,演示了伴生对象和伴生类的定义和使用:
1 |
|
特质trait
Scala语言中,有一个Scala语言中,有一个重要的概念叫做特质(trait),它类似于Java语言中的接口,但是比接口更加强大和灵活。
特质(trait)是一种定义了一组抽象或具体的属性和方法的类型,它可以被类(class)或对象(object)扩展(extends)或混入(mix in)。
特质可以实现多重继承,也就是说,一个类可以继承多个特质,从而获得所有特质中定义的属性和方法。
特质的定义和使用
特质的定义使用关键字trait
1 | trait PersonBody { |
但是特质不能被实例化,因此特质没有参数,也没有构造函数。像trait PersonBody(170) 或者 new PersonBody(170) 这样的写法就是错的,可以类比java的接口无法实例化
要使用特质,可以使用extends关键字来扩展一个或多个特质
扩展单个特质
1 |
|
注意,重写(实现)属性或方法时,需要使用override关键字来修饰
trait的方法声明必须被实现
扩展多个特质
使用with关键字来连接
1 | object Main { |
with后面可以跟with,来扩展很多特质
1 |
|
自身类型self-type
self-type表示一个类或特质依赖于另一个类型,即它必须和另一个类型混入(mixin)才能被实例化。
用一个简单的例子来解释Scala自身类型的概念。假设你有一个宠物猫,它有一些属性和行为,比如名字、颜色、叫声等。你可以用一个类来表示它:
1 | class Cat { |
现在,你想给你的猫添加一些新的功能,比如会说话、会唱歌、会跳舞等。你可以用特质来定义这些功能:
1 | trait Talkative { |
但是,这些功能并不是所有的猫都有的,只有一些特殊的猫才有。比如,只有会说话的猫才能唱歌,只有会唱歌的猫才能跳舞。你怎么表示这种依赖关系呢?你可以用自身类型来做到这一点:
1 | trait Talkative { |
这样,你就可以给你的猫混入这些特质,让它变得更有趣:
1 | val tom = new Cat with Talkative with Singer with Dancer // 创建一个会说话、唱歌、跳舞的猫 |
但是,如果你试图给一个不会说话的猫混入Singer或Dancer特质,就会报错:
1 | val jerry = new Cat with Singer // 报错:illegal inheritance; self-type Cat with Singer does not conform to Singer's selftype Singer with Talkative |
这是因为自身类型注解限制了混入特质的对象必须满足依赖类型的条件。这样可以保证对象在使用特质的成员时不会出现错误。
惰性列表LazyList(重点)
LazyList是Scala 2.13版本引入的新的集合类型,它是一种惰性求值的列表。惰性求值的意思是,列表中的元素只有在需要的时候才会被计算,而不是一开始就全部计算好。这样可以节省内存和时间,也可以表示无限的序列。
State,head及tail
| 名称 | 类型 | 作用 |
|---|---|---|
| state | 字段 | 存储LazyList对象的状态,表示惰性序列的结构和计算状态 |
| State | 特质 | 定义LazyList对象的状态的特质,有两个子类:Cons和Empty |
| tail | 方法 | 返回一个新的LazyList对象,包含除了第一个元素之外的所有元素,惰性求值 |
| head | 方法 | 返回LazyList对象的第一个元素,严格求值 |
State
1 | private sealed trait State[+A] extends Serializable { |
state
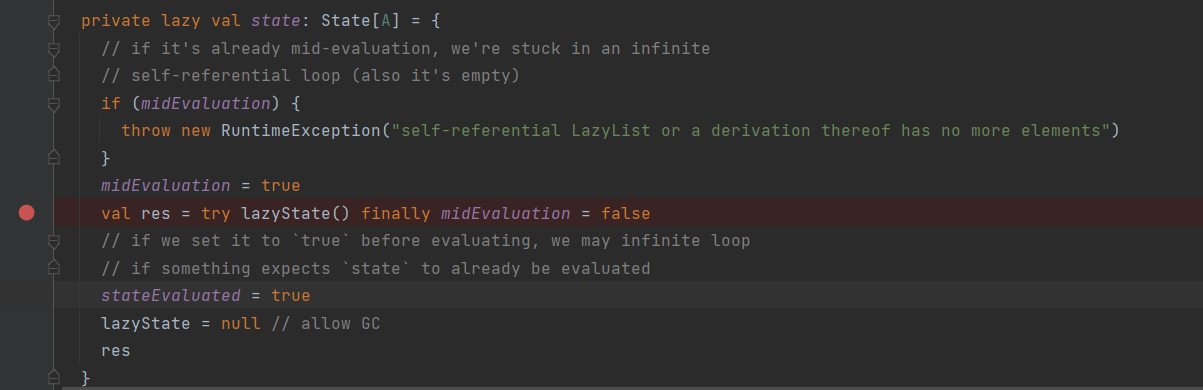
1 | private lazy val state: State[A] = { |
通过lazyState()方法去计算State的head和tail,保证LazyList的实时状态正确
关键字lazy表示延迟计算,也就是使用到的时候才会计算出结果
工作原理(关键)
光看上面的这几个成员会让人很头大,所以我用了很长一段时间才把他们的内在联系和整个LazyList体系的运行机制搞明白了
首先,我们创建一个存有无限个数字”1”的LazyList
1 | val ones = LazyList.continually(1) |
此时,我们println这个惰性列表,可以发现是全都没有计算的,会打印出LazyList(<not computed>)
之后,我们用drop方法取出第一个元素(索引为0),就要用到我们之前的head方法,返回LazyList对象的第一个元素。然后再次打印这个LazyList
1 | println(ones.drop(0).head) |
好了,到此结束,接下来我们分析一下LazyList的内部做了什么
内部流程
创建LazyList时,LazyList会接受一个参数lazyState(一般情况下用户不用管),这个lazyState是一个无参的匿名函数,这个匿名函数会返回一个State对象,这个State存储着head和tail方法
1 | private sealed trait State[+A] extends Serializable { |
这个匿名函数的head方法是:返回一个元素,这个元素是当前LazyList计算出的第一个元素
这个匿名函数的tail方法是: 返回一个新的LazyList,存储着除了第一个元素之外的其他元素(这里的”存储”并不是实际存在的,更恰当的说是表示其他元素的一个集合)
注意,此时匿名函数并没有被调用,也就是说state字段的head和tail都还没有实现
到目前为止,LazyList里面一个实际存储的元素都没有,所以会显示LazyList(<not computed>)
接下来,我们调用了方法来取出第一个元素
LazyList会使用state.head来获取第一个元素,此时需要用到state,所以懒加载的state字段开始初始化
1 | private lazy val state: State[A] = { |
state字段在初始化过程中,会调用lazyState()方法,这个lazyState就是LazyList的构造器接受的那个匿名函数。
1
val res = try lazyState() finally midEvaluation = false
lazyState方法执行完后会返回一个State对象,这个State的head方法返回数字1,而tail方法返回一个新的存着无限个1的LazyList
LazyList使用state.head方法获取到结果之后,把结果返回给drop.head的方法调用者
之后,如果未来还要取新的元素,那么我们所使用的LazyList就是tail方法返回的那一个新的存有无限个1的LazyList,而刚开始创建的那个LazyList就被垃圾回收器收走了
通过这个流程,我们可以看出惰性列表的本质,就是不停地用方法去取值,而不是一开始就存着[1,1,1,1,1……]在内存中
LazyList如何实现序列化与反序列化(关键)

SerializationProxy类,它是一个序列化代理,它是用来代替LazyList对象进行序列化和反序列化的类。
官方注解

翻译过来就是:
序列化代理用于将LazyList转换成一个可以存储或者传输的格式。
这个序列化代理适用于那些以一系列已经计算出来元素开头的LazyList。这些已经计算出来的元素会以一种紧凑的顺序格式进行序列化,然后跟着未计算出来的元素,它们使用标准的Java序列化方式来存储未计算出来的元素的结构。这样就可以实现对长的已经计算出来的惰性序列的序列化,而不会因为递归地序列化每个元素而耗尽栈空间。
序列化
1 | private[this] def writeObject(out: ObjectOutputStream): Unit = { |
流程可以分为以下几步:
- 调用out.defaultWriteObject()方法,这是一个标准的序列化操作
- 使用一个while循环遍历LazyList对象中已经计算出来的元素,并且使用out.writeObject方法将每个元素序列化
- 遇到第一个未计算出来的元素时,跳出循环
- 序列化一个特殊的标记SerializeEnd,表示已经计算出来的元素结束了
- 使用out.writeObject方法将未计算出来的元素(也就是LazyList对象的tail)进行序列化
- 序列化结束
反序列化
1 | private[this] def readObject(in: ObjectInputStream): Unit = { |
流程可以分为以下几步:
- 调用in.defaultReadObject()方法,这是一个标准的反序列化操作。
- 创建了一个名为init的数组缓冲区,用来存储已经计算出来的元素。
- 使用一个while循环反序列化每个元素,并且判断是否是特殊的标记SerializeEnd。
- 如果不是,就将该元素添加到init数组缓冲区中;
- 如果是,就表示已经计算出来的所有元素都已经反序列化完了,跳出循环。
- 反序列化剩余的没有计算出的元素,并将其类型转换为LazyList
- 使用++:方法连接init和tail,重构LazyList
- 反序列化结束
漏洞分析
CVE-2022-36944的产生原因,简单来说就是scala的LazyList在反序列化时会调用一个无参匿名函数来更新LazyList的状态,而这个函数是是可以被控制的
首先是ObjectInputStream.readObject方法接受到伪造的序列化字节流之后,尝试反序列化LazyList,进而把控制权转交给SerializationProxy类的readObject方法
执行到++:方法,

跟进++:(没想到吧,我是个方法)

可以看到调用了prependedAll方法,但是在LazyList中重写了这个方法

跟进knownIsEmpty方法,

这里要让stateEvaluated为true,否则不会执行isEmpty方法
跟进isEmpty方法,

跟进state字段,
跟进LazyState函数,可以发现就是LazyList构造器接受的无参匿名函数

最终我们只需要提前将这个函数替换为符合条件的任意函数,就可以达到漏洞利用的效果
如何找到可利用的方法
从LazyList的构造器的参数定义中,可以看出,lazyState的要求是一个无参的匿名函数,其次这个CVE利用的是函数,并不能RCE,所以我们还需要找到标准java库或者scala库中可以使用的无参匿名函数
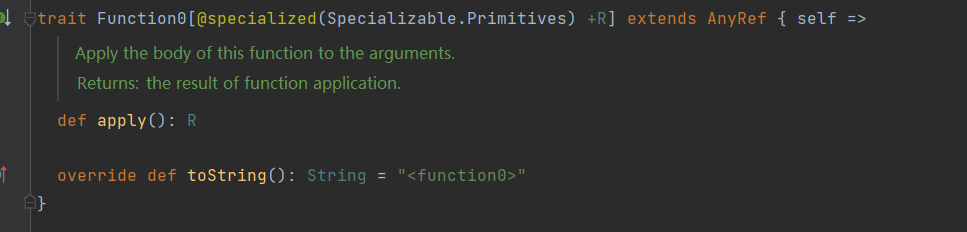
我们需要知道,在Scala中,所有无参匿名函数都会被编译器转换为实现了Function0接口的实例对象,
假如我们有以下代码:
1 | object Main { |
用scalac编译为class字节码
1 | scalac Main.scala |
javap反编译
1 | javap Main$.class |
scala编译器会为每一个伴生对象创建一个对象名(类名)+$结尾的类,类中的MODULE$静态成员就是伴生对象自身,存有自身的所有属性和方法

或者直接复制以下代码
1 | object Main { |
然后Ctrl+左键查看func的类型信息

可以看到编译器自动将func所表示的匿名函数转换为了Function0的实现对象
那么接下来的任务,就是要找到实现了Function0的所有类
查看POC中的DefaultProviders类,发现使用的都是以$$anonfun$$lessinit$greater$x 结尾的类,这些类
1 | scala.sys.process.ProcessBuilderImpl$FileOutput$$anonfun$$lessinit$greater$3 |
这里再稍微说一下这些类名是如何生成的,以scala.sys.process.ProcessBuilderImpl$URLInput$$anonfun$$lessinit$greater$1为例
Scala编译器在编译Scala代码时,会将匿名函数转换成Java字节码,这样就可以在Java虚拟机上运行。为了与Java兼容,Scala编译器会为每个匿名函数生成一个类,并给这个类一个特殊的名字,通常是
anonfun加上一些数字和符号。这个类名的作用是唯一地标识这个匿名函数,以便在运行时调用。
$URLInput:表示ProcessBuilderImpl的内部类
$$anonfun:表示匿名函数的前缀,表示这是一个自动生成的类。
$$lessinit$greater:是<init>的转义形式,表示这个匿名函数是在构造器中定义的。
$1:是匿名函数的序号,表示这是第一个匿名函数。
去追踪一下这个类,发现最多只能看到URLInput类

那如果直接用URLInput行不行呢,尝试把代码改一下
1 | public static Function0<Object> urlInput(Object[] args){ |
生成一下payload

发现报错,这是因为URLinput就是一个正常的类,而不是由Scala编译器转换过来的匿名函数,无法转换为Function0
所以说不能直接用URLinput作为利用方法
再回到scala.sys.process.ProcessBuilderImpl\$URLInput\$\$anonfun\$\$lessinit\$greater\$1,以及URLInput类的那行定义,
class URLInput(url: URL) extends IStreamBuilder(url.openStream(), url.toString)
猜测:当一个类继承了一个父类,并且这个被继承的父类的构造参数调用了子类构造参数的方法时,scala编译器会生成一个
带有$$anonfun$$lessinit$greater$类名的类。
做一个实验,
1 | class a(){ |
用sbt 生成字节码,查看生成的class

并没有生成带有\$$anonfun$$lessinit$greater$类名的类,感觉还是忽略了什么
去查看IStreamBuilder类,也就是被URLInput继承的类,
发现其第一个构造参数如下
1 | stream: => InputStream |
这里的=>可不是()=>{}的简写,而是一个新的概念,叫做传名参数
传名参数是一种特殊的参数类型,它表示参数的值不是在函数调用时就确定,而是在函数体内每次使用时才计算。
可以理解为惰性求值,需要传入一个函数
更改实验代码:
1 | package zhb |
clean一下,然后stb编译

多出来了c$$anonfun$$lessinit$greater$1.class,
url.msg()即使改为一个带有参数的方法,也依然会生成同名类
观察其字节码可以发现其调用的a.msg()

到此为止,类比推理一下,我们终于明白scala.sys.process.ProcessBuilderImpl$URLInput$$anonfun$$lessinit$greater$1这个编译器自动生成的类其实就是url.openStream()方法转换而来的,
也就是说,在LazyList计算state时使用的LazyState(),经过我们精心构造后被替换为了url.openStream()方法

对应的可利用函数还有如下:

对于url.openStream(),虽然他自身并不是匿名函数,理应是一个函数返回值。
但是因为自己是被作为传名参数调用的,这个方法只会再被需要使用时执行,所以会存留方法的引用或者说实现。
1 | object HelloWorld { |
又因为是作为父类的构造参数,所以scala编译器会为父类的传名参数生成一个实现了Function0类的子类,即使这个参数的实现方法参数可能不为0
对于FileInputStream和FileOutputStream的new方法,同理
综上所述,CVE-2022-36944的可利用方法的符合条件如下:
1.作为传名参数被使用
2.满足(1)的同时,作为父类的构造参数
3.存在于受害者服务环境中的classpath中
有兴趣的师傅可以再找找有没有其他可利用方法
漏洞复现
poc.cve.lazylist.payload.Main更改为Base64方式输出
1 | public class Main { |
victim改为对Base64进行反序列化
1 | public class Victim { |
urlInput
起一个http服务或者dnslog,
1 | public class Main { |
生成payload后,复制给poc.cve.lazylist.victim.Victim的data变量,执行

可以接受到http请求,但是无法弹shell
fileOutput
这个payload可以用来清空文件内容,比如黑名单
或者打开一个追加流,但没什么用
比如我们创建一个waf.txt,随便写点东西
1 | public class Main { |
生成payload后,复制给poc.cve.lazylist.victim.Victim的data变量,执行后清空文件内容
fileInput
文件输入流是用来读取文件的,所以在不能使用方法的前提下没什么用
心得感悟
断断续续用了一周左右的时间,从对scala的代码都看不懂到写完这篇文章,期间走了很多弯路,甚至想放弃,直到现在都无法相信自己能硬啃下来这个CVE,所以说,坚持不一定有好的结果,但一定会有收获。
最后,请允许我以崇高的敬意给予挖掘0day的安全研究员们,你们真的太厉害了