[GFCTF2021]文件查看器复现
考点:
1.php反序列化
2.可调用对象数组对方法的调用
3.编码转换的利用
4.php伪协议过滤器的利用
5.垃圾回收GC机制的利用
开局登录页面,输入admin,admin之后进入文件查看页面,并且扫描后发现有www.zip源码泄露
稍微探究一下,发现这个项目的设计模式很有意思
index.php
1 |
|
主要看3个php,Files,Myerror,User
只有User类有析构函数作为入口点,于是着手构造POP链子
这里链子的逻辑比较简单,就不赘述,下面主要讲一点涉及到的新特性

POP链:
1 | class User{ |
($this->password)();这个代码决定了我们只能使用没有this前缀的方法,比如phpinfo,而不能使用类中的方法(如check),原因是如果我们给password赋值为’check’,那么最终执行的就是check()而不是this->check()
所以这里面涉及到第2个考点:可调用对象数组对方法的调用
先看一个例子:
1 |
|
执行这段代码后会调用aA中的方法check,打印出’check’,这里涉及到PHP7引入的一个新特性 Uniform Variable Syntax,它扩展了可调用数组的功能,增加了其在变量上调用函数的能力,使得可以在一个变量(或表达式)后面加上括号直接调用函数。
也可以说是call_user_func($password)的语法糖
还有一个之前没见过的点,
1 | $test=$this->message->{$this->test}; |
这里涉及到的一个点叫做动态属性,其实含义上就是$this->message->($this->test),只不过php语法不允许这么用括号罢了
找上传点
代码中没有明显unserilizer,但可以写文件(虽然无法控制内容,这里先按下不表),这时候应该想到利用phar打反序列化
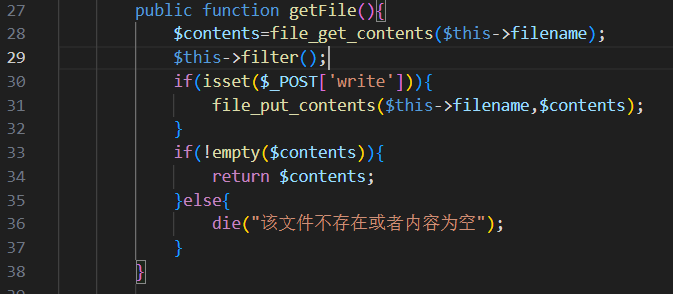
但是发现有过滤检测,无法使用phar://来反序列化

但我们可以观察发现,他是先执行file_get然后再检测,那么我们有没有办法用phar://反序列化后立即执行User的析构函数,这样我们反序列化完你爱怎么过滤就怎么过滤,跟我们没有关系
这时候要祭出我们的GC垃圾回收机制了
PHP的垃圾回收机制主要是为了解决内存泄漏的问题。
在PHP中,内存管理主要通过引用计数实现。每个PHP变量都有一个引用计数,当引用计数减少到0时,PHP就知道这个变量不再被使用,于是释放它所占用的内存。
关于引用计数,可以看PHP官方手册,解释的很清楚
垃圾回收机制
当运行垃圾回收器时,PHP会检查所有已经unset但引用计数仍大于0的变量,看它们是否真的无法访问)。如果是,那么PHP会删除这些变量并回收它们占用的内存。
对于这道题来说,我们虽然不能用unset来手动删除User的引用计数,但是我们可以通过另一种方法来使使PHP认为User类对象是一个没有被引用的垃圾,这样就能提前触发destruct
结合一个简单的例子加强理解
1 |
|
正常情况下,显示

我们更改一下这个序列化字符串,
1 | $str='a:2:{i:0;O:4:"User":0:{}i:0;s:1:"1";}'; |

可以发现User对象的析构函数在程序结束之前就执行了
这是因为,PHP在反序列化这个数组时,首先构建第一个元素User对象,此时索引[0]指向了这个User,引用计数为1,之后在我们的手动改造下索引[0]又指向了第二个元素1,之前创建的User对象失去了唯一的引用,触发了GC机制,于是PHP垃圾回收器提前删除了这个对象,所以也就提前执行了析构函数
还有一种情况
1 | unserialize($str); |
如果是直接反序列化而不给赋值的话,也会提前执行析构函数
我们要用这个机制来绕过filter检测
Phar修复
把生成的phar丢进010或者Winhex,手动修改第二个元素索引为0,用脚本重新签一下名
1 | from hashlib import sha1 |
PHP官方对于签名结构的讲解,一共28个字节,比较简单
PHP: Phar Signature format - Manual
上传Phar
关键是这两个函数:read,getFile
1 | public function read(){ |
虽然表面上不能控制写的内容,但是通过伪协议和过滤器是可以改变一些文件内容的
现在我们万事俱备,只欠如何上传phar到靶机中,这里用到报错日志error.txt
直接复制二进制文件肯定是不现实的,我们这里用base64编码试试
勾选重写,让报错信息带着编码过的信息一起写进去
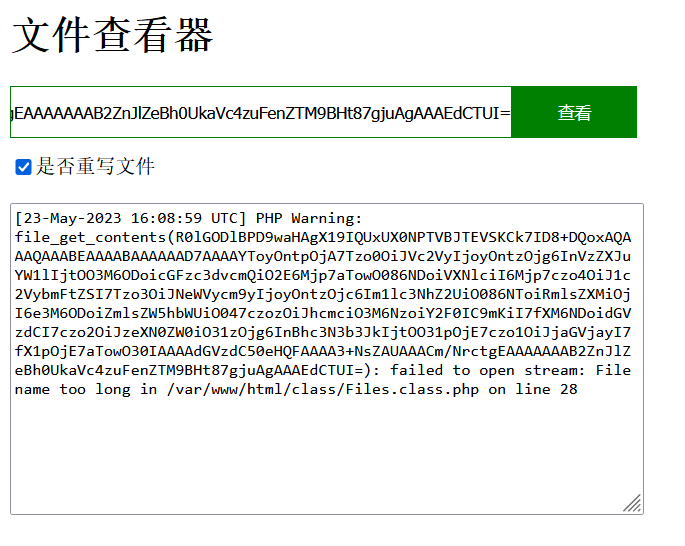
再用php://filter/read=convert.base64-decode/resource=log/error.txt解码报错,这是因为解码的是整个error.txt,其中包括了其他非编码信息,而Base64会将所有数字,字母/+=都认为是需要编码的
所以我们需要将除了我们自己的payload之外的全部转换为乱码,这样Base64就会忽略那些乱码,只解码我们自己的payload
UCS-2编码
UCS-2 编码使用固定2个字节,所以在ASCII字符中,在每个字符前面会填充一个 00字节(大端序),但将报错信息写入error时并不是二进制,所以我们不能直接传递00字节
1 | lanb0 |
Quoted-Printable编码
“Quoted-Printable”编码的基本原则是:安全的ASCII字符(如字母、数字、标点符号等)保持不变,空格也保持不变(但行尾的空格必须编码),其他所有字符(如非ASCII字符或控制字符)则以”=”后跟两个十六进制数字的形式编码
1 | lanb0\n |
可以通过这个编码来把00字节当做ASCII字符传进error.txt
综上所述,我们的思路就是:把phar的二进制数据先用base64编码,然后用UCS-2编码(相当于给我们自己的payload打上’标记’,这个标记就是’00’),最后用Quoted-Printable来解决00字节的无法传递问题
一键编码脚本
1 |
|
在 Quoted-Printable 编码中,为了防止编码后的字符串过长,通常会在每76个字符后插入一个软换行,也就是
=符号加上一个换行符。
最终利用
复制编码后的内容,传到error里

接下来的步骤需要按顺序来,并且需要勾选重写选项
解码quoted-printable
php://filter/read=convert.quoted-printable-decode/resource=log/error.txt
解码UCS-2
php://filter/read=convert.iconv.UCS-2.UTF-8/resource=log/error.txt
解码base64
php://filter/read=convert.base64-decode/resource=log/error.txt
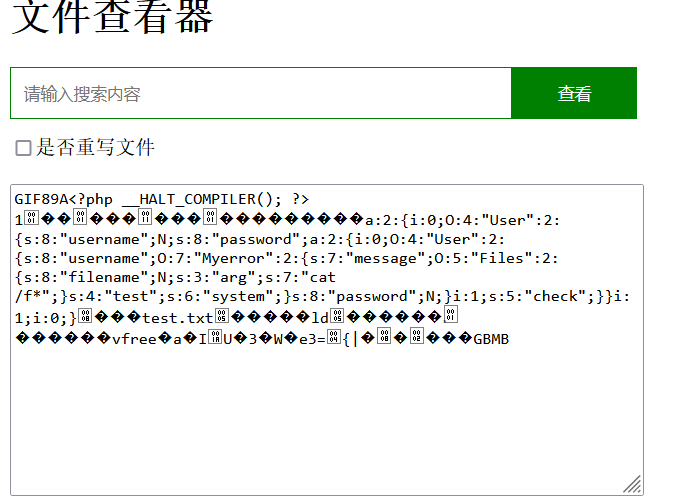
到这一步时,最后用phar://log/error.txt来反序列化rce