
大数阶乘算法
例题讲解
算法与设计 第三章 【例题9】 P79
C++版完整代码:
1 |
|
代码讲解:
一.变量
1 | long a[256],b,d; |
n:计算谁的阶乘就把n赋值给谁
long a[256]:阶乘的结果按由低位到高位存储在数组a中(为节约空间,规定一个数组元素存储最多6位数字,如果按一个数组元素存储一位数字的话,浪费空间)
但其实int类型的数组一个元素也能存6位数

b:存储计算的中间结果(也就是阶乘过程中每一次累乘的结果)
d:存储超过6位数后的进位(因为我们规定的是一个数组元素最多存6位数)
m:数字的位数/6,也就是a数组中实际有效值的个数(从高往低,完整地计算完阶乘结果后若该数组元素依然全为0,则是无效)

图中红线为无效值(也叫填充值),黄线为有效值
1 | m=log(n)*n/6+2;//估计阶乘结果的位数 |
为什么m是这个表达式呢?
最主要的是*log(n)n,
实际上,这个m是估量n!的数量级的斯特林公式的近似(Stirling’s Approximation)表达式
斯特林公式原表达式:
$$
n! ≈ √(2πn) * (n/e)^n
$$
要估计n!的位数,我们可以取这个近似值的对数(以10为底)
$$
log10(n!) ≈ log10(√(2πn) * (n/e)^n)
$$
根据对数的性质,我们可以将其拆分为:
$$
log10(n!) ≈ log10(√(2πn)) + log10((n/e)^n)
$$
由于n较大,因此√(2πn)项相对于(n/e)^n项的影响较小,可以忽略。所以我们可以近似为:
$$
log10(n!) ≈ log10((n/e)^n) = n * log10(n/e)
$$
这就是位数的估计值,但因为我们用数组a的存储结果的形式规定的是每6位数字为一个数组元素,所以我们需要在位数的基础上除以6
最后的+2是一个安全边际,用于确保分配给数组的空间足够容纳计算结果。虽然log(n) * n / 6已经给出了一个近似的位数估计,但在实际编程中,为了防止数组溢出,通常会添加一些额外的空间
二.算法过程
1 | a[1]=1;//当n>0时,阶乘是从1开始累乘的,所以我们要给最开始的元素赋值为1 |
1 | for(i=2;i<=m;i=i+1){ |
1 |
|
这一段代码是阶乘运算的核心部分
为了更直观的感受计算过程,我们可以在每一步计算后输出a,b,d的值
1 |
|
部分结果:
开始部分

可以看到,因为一开始的a[j],b,d都太小,导致从第二次运算开始,计算的结果一直是0,也正好对应了书本上P80页的算法说明中的第(1)条中说的:
算法中m=log(n)n/6+2;是对n!位数的粗略估计。这样做算法简单,但效率较低,因为有*许多不必要的乘0运算
造成这样的现象的原因是:事先计算好了m的位数,在内层for循环中对每一个n都要运算m次,但实际上,我们前几次的计算只需要计算1次就够了,因为当b/1000000为0时,说明b,也就是当下的这轮计算结果是没有超过6位数的,自然也不需要手动进位,所以也不需要计算a[j+1]
用最简单的话总结一下,就是因为m被我们提前估算了,所以每次计算乘法都相当于最后的一轮的计算量,而到了最后一轮a中的元素已经非常多了,所以每一个数组元素都需要参与乘法计算
1 | if(d!=0){ |
这段代码是在包裹在i循环中,执行完j循环后的代码,也就是计算完此轮乘n后,通过d判断来判断是否需要进位(因为如果d=(b/1000000)大于0,说明b作为中间计算结果超过了6位,则需要进位)
所以每一层for(i=2;i<=n;i++)中做的事就是通过内层循环,计算a数组中每一个元素中存的值,内层循环后会判断是否需要进位,如果需要进位那么a的有效值的最高一位就赋值d(这里注意a[j]并不是覆盖了j循环中最新的j,因为在最后一次j循环结束后j加了1)
后面的代码就简单很多了,基本都是输出打印
1 | for(i=m;i>=1;i=i-1){ |
这段代码对应书中P81页算法说明(2)的第一句
输出时,首先计算结果的准确位数r

红箭头就是从最高位开始扫,一直扫到a[i]!=0时,r=i,也就是a数组有效值的最高位
1 | for(i=r-1;i>=1;i=i-1){ |
这里也对应了书上接着后面的话
在输出其他存储单元的数据时要特别注意,如若计算结果是123 000 001,a[2]中存储的是123,而a[1]中存储的不是000001,而是1.所以在输出时,通过多个条件语句才能保证输出的正确性。
如果a数组当前的元素的值大于99999,说明在1 000 00 - 9 999 99之间,刚好满足6位数,不需要填充0;
如果a数组当前的元素的值大于9999,说明在1 000 0 - 9 999 9之间,5位数,需要填充1个0;
如果a数组当前的元素的值大于999,说明在1 000 - 9 999 之间,4位数,需要填充2个0;
如果a数组当前的元素的值大于99,说明在1 00 - 9 99 之间,3位数,需要填充3个0;
如果a数组当前的元素的值大于9,说明在1 00 - 9 99 之间,2位数,需要填充4个0;
如果以上条件均不满足,说明在0 - 9 之间,1位数,需要填充5个0;
最终结果:

再回到我们刚才说过的,太多无意义的乘0运算,我们想要优化一下,按照书上的思路就是:给m设置初始值为1,当需要进位时,也就是每一轮计算完的d不为0时,m才加1.这样我们就会省去所有的无意义乘0运算
更改的部分:
1 | //m=log(n)*n/6+2; |
再来看更改后的运行步骤

可以看出,优化后的代码就没有无意义的乘0运算,实现了算法的效率提升
对比一下相比于原来的算法,优化后的算法提高多少效率
原本的算法:
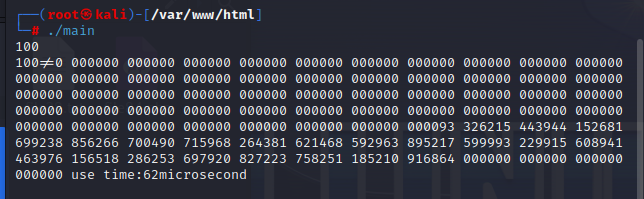
用时62微秒
优化后的算法:
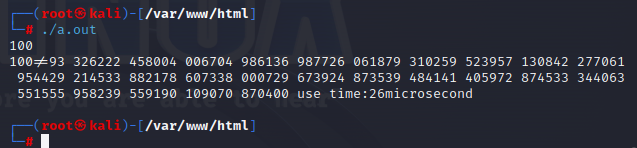
用时29微秒
为什么效率提升这么快?
总的来说就是在前几次,a数组只有前几个元素是有效值的时候,我们只需要用那几个元素与n相乘,而在原本的算法中,从一开始就把a的m个元素和n相乘,所以速度慢很多